

Meta da un paso adelante en la búsqueda de la preservación del lenguaje y la difusión de la tecnología de texto a voz y de voz a texto. La empresa de Mark Zuckerberg creó MMS, una Inteligencia artificial que sirve para identificar más de 4 mil idiomas hablados.
PUBLICIDAD
Massively Multilingual Speech, tal su nombre original, es una herramienta para “facilitar a las personas el acceso a la información y el uso de dispositivos en su idioma preferido”, según explica Meta.
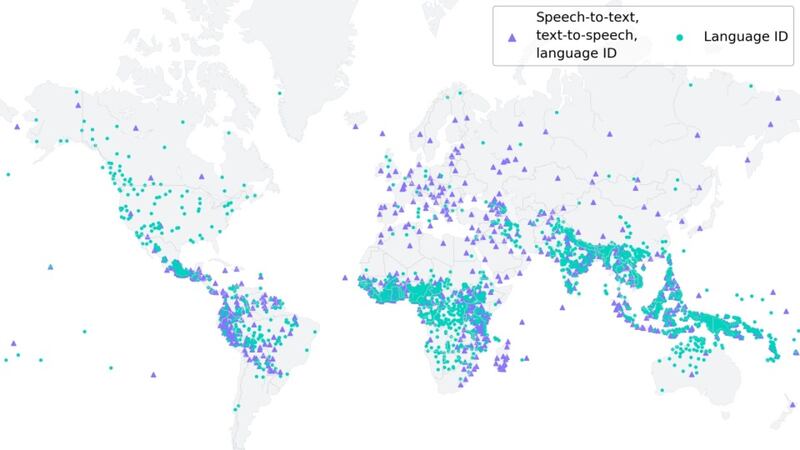
Este modelo amplía la tecnología de texto a voz y de voz a texto de alrededor de 100 idiomas a más de 1.100, además de identificar más de 4 mil idiomas hablados.
“Estamos abriendo nuestros modelos y código para que otros en la comunidad de investigación puedan desarrollar nuestro trabajo y ayudar a preservar los idiomas del planeta, acercando al mundo”, recalca la empresa de Mark Zuckerberg.
Meta utilizó la Biblia y otros textos religiosos para alimentar la Inteligencia Artificial
Hay una base religiosa en la labor de la empresa de Zuckerberg. Meta utilizó textos como la Biblia para alimentar la Inteligencia Artificial.
Meta recopiló un conjunto de datos de lecturas del Nuevo Testamento en más de 1.100 idiomas, proporcionando un promedio de 32 horas de datos por idioma.
“Al considerar grabaciones sin etiquetas de otras lecturas religiosas cristianas, aumentamos el número de idiomas disponibles a más de 4 mil”, explica Meta. MMS funciona con voces masculinas y femeninas sin ningún problema.
PUBLICIDAD
Los investigadores del laboratorio de IA de Meta trabajaron con un algoritmo diseñado para alinear las grabaciones de audio con el texto que las acompaña, explica MIT Technology Review.
Acto seguido, repitieron el proceso con un segundo algoritmo, entrenado con los datos recién alineados. Finalmente, MMS aprendió de manera más sencilla un nuevo idioma, sin necesidad del texto.
“Podemos usar lo que aprendió el modelo para construir rápidamente sistemas de voz con muy, muy pocos datos”, señala Michael Auli, científico investigador de Meta. “Para el inglés, tenemos montones y montones de buenos conjuntos de datos, y los tenemos para algunos idiomas más, pero simplemente no tenemos eso para los idiomas que hablan, digamos, mil personas”.
Por los momentos, MMS aún corre el riesgo de transcribir incorrectamente determinadas palabras o frases. Además, sus modelos de reconocimiento de voz generaron más palabras sesgadas que otros modelos, un 0.7% más, según MIT Technology Review.


